As more and more .NET developers use .NET obfuscators to protect their products, they encounter the question of how to properly use obfuscators, as they require certain configurations. You can’t just run a single “magic” command to make your .NET application secure from hackers. In this article, we will look at how to configure an obfuscator to get the most benefit from using it.
Contents
Overview of Obfuscation Techniques
There are several levels of protection: obfuscation of class names, methods, etc., control flow obfuscation, and virtualization. By obfuscating names, we hide the application’s logic because class, method, and field names contain information about what each piece of code is responsible for. This method does not directly alter the code of methods, so name obfuscation provides the weakest level of application protection.
Control flow obfuscation and virtualization modify method code, but in different ways: control flow obfuscation hides the logic of conditional and unconditional branches and loops by transforming the method’s code into a single loop that executes each “branch” of code. A “branch” of code is a sequence of instructions without any transitions, meaning it is always executed sequentially.
Virtualization represents a more advanced level of protection: while control flow obfuscation operates on code “branches”, virtualization processes each MSIL instruction individually. Each instruction has a primitive logic: take values from the stack, perform some operation on them, place the result back on the stack, or transfer control to a specific instruction. However, there is no actual stack (it is imaginary, as are method arguments and variables); the JIT compiler can generate any code for the processor’s execution, as long as the result aligns with the logic of the instructions.
But what if you create an actual stack, allocate memory for variables, and execute each instruction as designed, meaning actually taking values from the stack and putting the results back? This process would resemble an instruction interpreter. The code for such an interpreter is the result of virtualization. If the original instructions and their operands are encoded in a specific way, reconstructing the original code becomes an exceedingly difficult task.
How to Choose Obfuscation Techniques?
A question might arise: which obfuscation method should be used and when? And why not use them all? After all, it seems that the more we obfuscate, the harder it will be to “hack” our application. However, it’s not that simple. Name obfuscation hides part of the information about the application’s structure and does not affect its performance since the method code remains unchanged. Therefore, it can indeed be used alongside obfuscation methods that alter method code: control flow obfuscation and virtualization. Below you can find an infographic that describes possible combinations of obfuscation approaches:
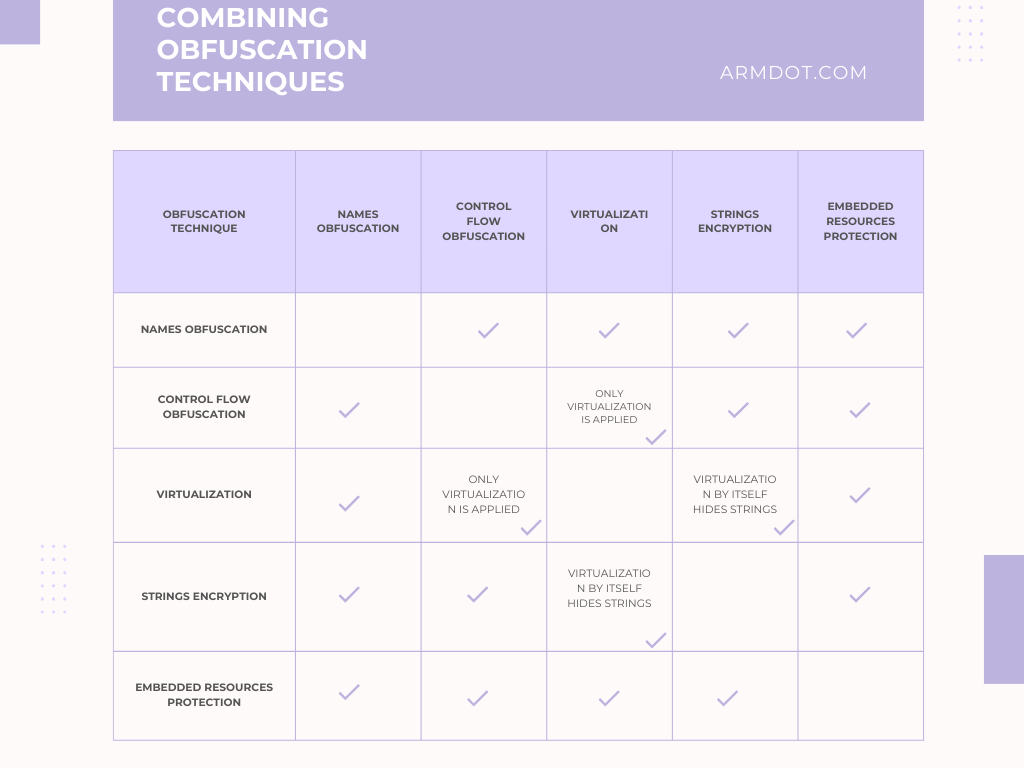
These latter two obfuscation methods do affect performance: control flow obfuscation to a lesser extent, and virtualization to a greater extent. Therefore, the correct approach appears to be dividing the entire application code into three parts based on the importance of ensuring that a specific method is not “hacked”.
You can select a few (let’s say one, ten, twenty—depending on the complexity of your application) of the most sensitive methods to “hacking” and virtualize them. Then, choose less critical methods and apply control flow obfuscation to them. The remaining methods can be left as they are: indeed, if all a method does is display an About window, is it worth obfuscating? It’s a rhetorical question.
There are two additional obfuscation methods that deserve attention: string encryption and embedded resource protection. String encryption is aimed at complicating the search for strings in the application’s code, as strings often contain sensitive information, such as database connection strings. String encryption can be used alongside control flow obfuscation and virtualization, although this is redundant in the case of virtualization since each `ldstr` instruction will already be securely concealed.
As for embedded resource protection, this method does not alter the application’s method code. Therefore, it is also compatible with other obfuscation methods.
Summary
While obfuscators offer a wide array of obfuscation techniques, it is important to understand which ones can be combined and how they might affect the application’s performance after obfuscation. This is why virtualization should be applied only to a limited number of methods for which code protection is the highest priority. Embedded resource protection and name obfuscation do not affect performance and can be used in conjunction with other protection methods.
Naturally, it’s essential to establish automated testing for the obfuscated application because, for example, after renaming classes or methods, any code that relied on their original names (such as when using reflection) will fail.